시맨틱웹
시맨틱웹으로의 진화
기존 웹에서의 문제점은 바로 웹상에 게시되는 모든 정보들이 단지 사람만을 위한다는 것이다. 즉, 사람만이 이해할 수 있다는 의미이다. 예를 들어, [그림 1]과 같이 대부분의 웹페이지들은 단순히 HTML 코드로 이루어져 있다.
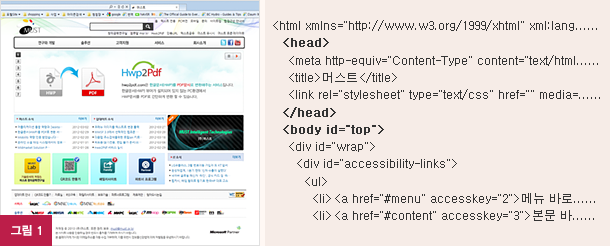
- 첫 번째 문제로, 웹 정보검색의 문제점들을 생각해 볼 수 있다. 웹으로 쏟아져 들어오는 지식 정보의 양이 6개월마다 두 배가 된다고 한다. 우리가 웹에서 원하는 정보를 "비교적" 용이하게 찾을 수 있는 방법은 대표적으로, 검색 엔진들을 사용하는 것일 것이다. 하지만 웹 정보의 인덱싱 과정에서 웹로봇들은 중요한 의미있는 정보들을 놓치게 된다. [그림 1]에서 이 웹페이지가 어떤 정보를 포함하고 있는지 또는 "Mon 11am - 7pm"이 어떤 시간에 대한 정보라는 사실을 자동으로 이해하고 인덱싱 하기는 어려운 일이다.
- 두 번째 문제는 이형(Heterogeneous) 시스템간의 통합에서 발생할 수 있다. 이형 데이터베이스 간의 데이터들을 통합한다고 했을 때, 데이터베이스 스키마(Schstronga)나 레코드들에서 사용되는 키워드들 간의 동음이의어와 같은 언어학적인 문제에 의해 스키마들 간의 매칭(Matching)을 자동화하기 어렵다. 이와 같은 문제점에 의해 기계는 다중의 정보를 서로 비교하고 융합하는데 어려움을 겪게 된다.
- 예를 들어, 다음과 같은 요청을 받았다고 하자.
- "인천에서 6월 6일 오전 10시 이후에 출발하여 프랑스 파리에 있는 호텔을 예약하라"
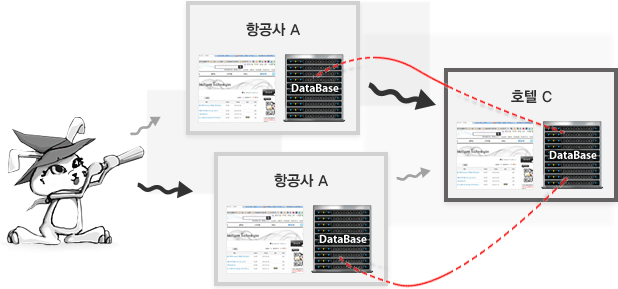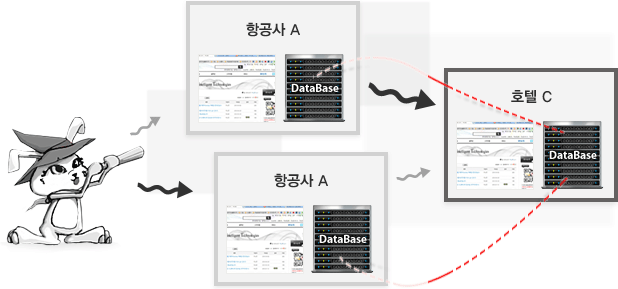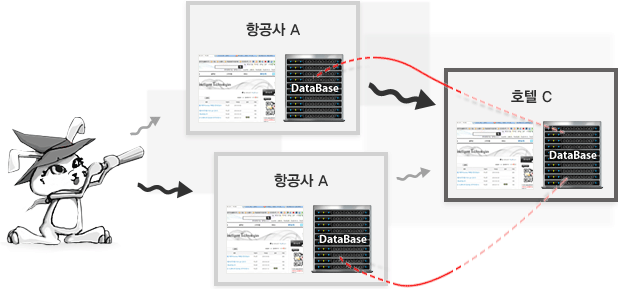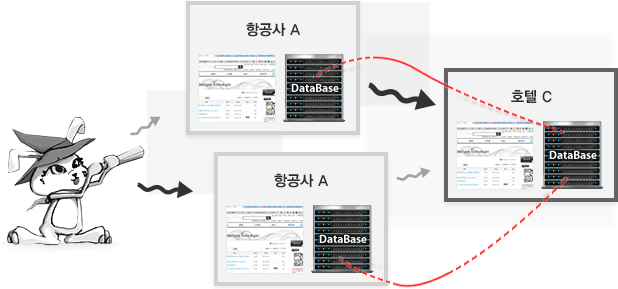
- 우리는 우선 인천에서 파리까지 가는 항공편을 알아보기 위해 항공사 웹사이트를 방문하고, 파리 도착에 맞춰서 파리에 있는 호텔 웹사이트에 방문하여 예약 작업을 수행할 것이다. [그림 2]에서 검은색 화살표들과 같이 사람에 의한 순차적으로 해당 웹페이지들에 접속을 통해 작업을 수행할 것이다. 하지만, 이와 같은 명령을 기계가 자동으로 수행할 수 있게 하려면 어떻게 해야 할 것인가? 시맨틱 웹에서는 앞에서 말한 것처럼 정보 소스들간의 상호운용성(Interoperability)을 위해 [그림 2]의 빨간색 실선들과 같이, 데이터베이스들 간에 스키마 매칭이 가능해야한다.
- 시맨틱 웹은 앞에서 언급한 문제점들을 해결하고자 사람뿐만 아니라 기계가 이해 할 수 있도록 하는 것이다. 원래, 시맨틱 웹에 대한 정의는 다음과 같다.
- "I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web - the content, links, and transactions between people and computers. A 'semantic Web', which should make this possible, has yet to strongerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The 'intelligent agents' people have touted for ages will finally materialize."
- 즉, 시맨틱 웹은 지능형 에이전트와 같은 기계들 간의 자동화된 정보 및 지식의 공유를 통해 인간들에게 다양한 분야에서 효과적인 서비스를 제공하기 위한 환경이라고 생각할 수 있다. 그렇다면, 시맨틱 웹의 구현을 위해 필요한 것은 무엇일까? 다음과 같이 크게 4가지 요소를 생각해 볼 수 있다.
- Explicit metadata
- 온톨로지(Ontology)
- Logic and Inference
- Agents
온톨로지
온톨로지란 관심 영역 내 공유된 개념화에 대한 형식적이고 명시적인 명세화이다.
- Ontology Web Language (OWL)
- 컴퓨터가 정보를 표현함에 있어 사람에게 국한되지 않고 정보의 내용을 직접 처리할 수 있는 어플리케이션을 구현하는데 활용될 수 있도록 설계된 언어
- semantic Web을 위한 언어
- 기계 해석이 가능한 웹 컨텐츠를 저작함에 있어 XML, RDF, RDF-Schstronga보다 뛰어난 언어.
- 속성과 클래스에 대하여 기술할 수 있는 더 많은 어휘를 제공
* 비접합성, 관계차수, 동치성, 풍부한 속성타입, 속성의 특성
- OWL 종류
- OWL-Lite : 클래스 분류계층과 간단한 제약사항(0, 1 차수)
- OWL-DL : 유한한 시간에 완벽한 결론을 낼 수 있는 범위에서의 최대의 표현력을 활용 (Description Logic - 기술논리)에 기반
- OWL-Full : 최대의 표현력과 RDF의 유연한 문법을 모두 활용
특히, 온톨로지는 지식을 저장할 수 있는 중요한 역할을 한다. 본래 온톨로지는 철학 분야에서 사물의 본질과 현상에 대한 학문이다. 전산학 분야에서는 특정 도메인 내에서 사용되어지는 개념(Concept)들과 그 개념들 간의 관계를 표현하고 저장하고 있는 데이터 모델로 이해할 수 있다. 온톨로지의 다른 한 가지 특징은 "Shared Conceptualization"이다. 즉, 각각의 정보시스템이 가지고 있는 온톨로지에 내포하고 있는 의미정보(semantic)는 다른 정보시스템들과 공유가 가능해야한다는 것이다. 그렇기 때문에, 시맨틱 웹에서 온톨로지가 중요한 이유라고 볼 수 있다. 온톨로지의 연구가 활발히 진행되어 왔고, 다양한 종류의 온톨로지가 개발되어짐에 따라, 우리는 아래 내용과 같이 온톨로지들을 구분 정리할 수 있다.
먼저Upper-level 온톨로지는 다양한 영역에서 공통으로 사용되어지는 일반적인 개념들을 정의한 것이다. 반면에 각 영역에서만 사용될 수 있는 구체적인 개념들은 그 영역에 해당하는 Domain 온톨로지에 저장되어진다. 특히, 최근 개인화된 정보시스템(예를 들면, 확장된 블로그의 형태)에 대한 관심이 증가하면서, 개인 온톨로지(Personal Ontology)에 대한 연구가 활발히 진행되고 있다. 그러면, 그와 같은 온톨로지들은 어떻게 표현 및 생성되어지며, 웹과 어떻게 연동되는지 알아보자. 이제 우리는 온톨로지 언어(Ontology Language)에 대해 알아보도록 하겠다. 현재까지 다양한 온톨로지 언어들이 개발되어왔으며, 대표적으로 W3C 표준이라고 할 수 있는 OWL(Web Ontology Language)가 가장 널리 사용되고 있다.
OWL은 기본적으로 RDF(Resource Description Framework)의 확장이며, XML 문법을 따른다. OWL은 의미의 표현 정도(Expressive Power)에 따라 OWL-Full, OWL-DL, OWL-Lite로 크게 나누어진다. 예를 들어 Univerity 온톨로지를 다음과 같이 표현된다. 크게 세 부분으로 나누어지는데, 헤더부분으로써 간단히 온톨로지 내에서 사용되는 Vocabulary들의 Namespace를 정의하고 있다. 다음은 이 온톨로지의 간단한 설명과 이름들에 대한 정보를 기입한다. 마지막으로 이온톨로지 내에 있는 개념(owl:Class)들과 개념들 간의 관계(owl:subClass, owl:disjointWith, owl:equivalentClass)들을 정의하고 있다. (자세한 내용은 W3C 웹페이지(http://www.w3.org/TR/owl-guide/)를 참조하시기 바란다.)
OWL 온톨로지는 여러 가지 형태로 사용되어질 수 있다. 단독으로 의미정보(semantic)만을 제공할 수도 있으며, 기존의 웹 페이지에 게시되어 있는 정보를 주석(Annotation)하기 위한 메타 데이터 역할을 할 수도 있다.
시맨틱웹에서의 응용 사례들
과연, 온톨로지를 웹에 적용함으로써 앞에서 언급한 정보 검색 문제점들을 해결 할 수 있을까? 현재까지 시맨틱웹 연구 결과물들을 종합해 보았을 때, 다음과 같이 정리될 수 있다.
쿼리 확장 및 변환
사용자가 제시한 쿼리(즉, 검색어)로부터 사용자가 의도한 의미(semantic, 또는 Context)를 추출(인식)하여 쿼리를 확장한다거나 변환하여 검색하도록 한다. 이와 같은 서비스를 위해서, 시맨틱웹 마이닝 (semantic Web Mining), 시맨틱웹 개인화 (semantic Web Personalization)같은 기술들이 적용 가능하다.
온톨로지 매칭
정보 소스들간의 자동화된 상호운용성을 지원하기 위해서는 각각 정보소스들의 온톨로지들 간의 매칭이 선행되어야한다. 항공사A에서 사용하고 있는 온톨로지 Onto1의 Class A가 호텔 B의 온톨로지 Onto2의 Class B와 "Equivalent"함을 발견한다면, 우리는 다행한 형태의 정보공유 시스템을 구현할 수 있을 것이다. 현재 수많은 온톨로지 매칭 알고리즘들이 발표되었다.
시맨틱 어노테이션
전자 도서관(Digital Library)나 박물관(Museum) 같은 곳에 적용되고 있다. 특히, 문화 유산(Cultural Heritages)과 같은 정보는 다양한 형태(사진, 음악, 동영상)로 표현되어 있다. 더욱 중요하게, 역사적인 시간과 장소에 대한 지식을 각각의 해당 자원에 어노테이션 해야하는 중요한 응용 분야라 할 수 있겠다.
시맨틱웹과 Web 2.0
- 첫 번째 가능성으로서, 웹 2.0 시스템들은 시맨틱 웹 기술을 이용함으로써 사용자들에게 보다 향상된 "참여"와 "공유" 서비스를 제공할 수 있다. 현재 블로그와 같은 웹 2.0 시스템의 어노테이션을 위해 FOAF (Friend-Of-A-Friend, http://www.foaf-project.org/) 와 SIOC (semantically Interlinked Online Communities, http://sioc-project.org/)와 같은 온톨로지가 개발되었다.
- 두 번째로 생각해 볼 수 있는 방법은 웹 2.0 기술을 시맨틱 웹 시스템에 적용하는 것이다. 특히, 최근에서는 태킹 기능이 보완되어, 폭소노미를 이용하므로 둘 이상의 카테고리에 속하는 정보의 분류가 용이해졌다. URL과 제목뿐만 아니라 태그, 메모, 참조 등의 부가정보를 첨가할 수도 있도록 하여 쿼리 기반의 검색 기능과 함께, 브라우징 기반의 정보 검색을 가능하도록 하였다. 특히 원하는 만큼의 태그를 자유롭게 사용할 수 있으므로 자신의 북마크를 연상하는데 도움이 된다.
- 향후, Web2.0에서의 집단지성은 semantic Grid (또는 Knowledge Grid) 환경으로 확장성을 기대해 볼 수 있다. 기본적으로 사용들이 표현하는 지식(소셜 북마킹 시스템의 경우, 태그)들이 융합되고 통합되기 위해서는 그 지식의 의미(semantic) 와 상황(Context)을 이해하고 비교할 수 있어야 한다.
Web 2.0 참고문서
출처
영남대학교 정재은 교수 (머스트 자문교수)

